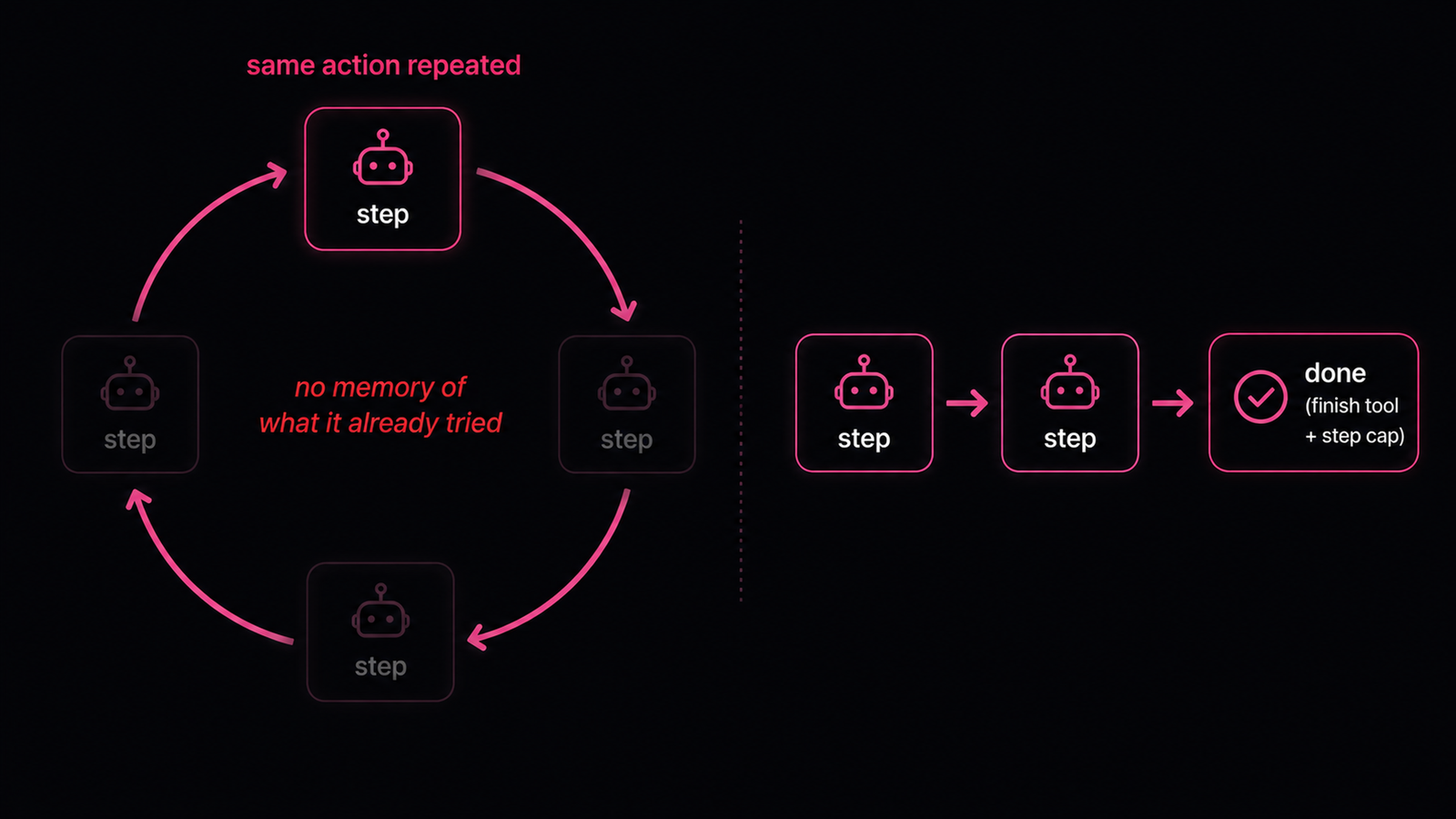
Short answer. Your agent loops because its only memory is the growing transcript, and a basic reason-act loop has nothing that says "I already tried this exact step and it failed." So it treats the situation as new and repeats the action. Step repetition is the single most common agent failure mode, 15.7% of cases in the Berkeley MAST study. The fix is not a smarter model. It is external state, a hard step cap, and an explicit finish condition.

With no memory of what it already tried and no required stop signal, the agent cycles. A step cap and a finish tool give it an exit.
Key facts.
- Step repetition is the most common single failure mode in multi-agent systems, at 15.7% of all failures; "unaware of termination conditions" adds another 12.4% (Cemri et al., MAST, 2025).
- The waste is large: one 8B model averaged 26.4 redundant steps out of 40 in ALFWorld, and early-exit mechanisms cut redundant steps by 50 to 70% with only minor performance loss (early-exit behavior of LLM agents, 2025).
- The classic reason-act loop has no built-in progress tracking or cycle detection, so production frameworks hard-code a max-iteration cap precisely to stop runaway loops.
- It gets expensive: one documented sandbox agent stuck recursively provisioning cloud clusters ran up about $12,000 before anyone caught it (reported, Towards AI, 2026).
Why does an agent repeat itself at all?
Because it has no durable memory of its own actions. A reason-act agent runs a simple cycle: think, call a tool, read the result, repeat, with the whole transcript fed back each turn. If the result is not clearly incorporated, or the history gets truncated, the next step sees the task as fresh and picks the same action again. Worse, the model self-conditions on its own output: once it generates a repetitive thought, that thought is now in the context as established behavior, so the next turn reinforces it. There is no external note that says "I already searched this and it returned nothing." Without that, the agent has no reason not to try the same thing a third, fourth, and fifth time. The loop is a memory problem, not an intelligence problem.
Why doesn't it just stop?
Because stopping is left to the model's judgment, and judgment is exactly what fails under ambiguity. In most agent loops, termination is implicit: keep calling tools until you decide to output a final answer. If the prompt never gives crisp completion criteria, or the model does not recognize them, the agent keeps going. The MAST study found "unaware of termination conditions" in 12.4% of failures, and it showed up almost entirely in failed runs, not successful ones. So the agent that cannot tell it is done is the same agent that fails the task. Leaving the exit decision to a model that is already confused is how a short task becomes an unbounded one.
In one ALFWorld run, 26.4 of 40 steps were redundant. Most of the work an unguided agent does is repeating itself.
How bad does it actually get?
Worse than it looks, because the loop burns time and money silently. The measured case is stark: an 8B model spent 26.4 of 40 steps on redundant actions, meaning roughly two-thirds of its work was repetition. In production the cost is not just latency. One documented sandbox agent got stuck recursively spinning up Kubernetes clusters to fix a simple error and accrued about $12,000 in cloud charges before a budget alarm caught it at 3 in the morning. A loop with no cap does not fail loudly. It keeps paying the meter until something external stops it, which is why every serious deployment treats an iteration cap as a safety belt, not an optimization.
How do you stop the loop?
| Fix | What it does | How |
|---|---|---|
| Step budget | Guarantees termination | Hard max-iteration cap; bail out and escalate when hit |
| Loop detection | Catches the repeat early | Track recent actions; if one repeats, block it and force a new approach |
| Explicit finish | Removes the guesswork | A dedicated "submit answer" tool plus clear, checkable done criteria |
| External state | Gives it a memory | Keep a checklist of what was tried and its result, outside the context window |
| Forced reflection | Breaks the cycle | After N stuck steps, trigger a critique step: "what have you tried, what is new" |
The strategic point is that loops are a design gap, not a model defect, so the fixes are cheap and reliable once you treat them as required. Cap the steps, detect repeats, give the agent a real finish signal, and hold its progress in state it cannot forget. The harder question is which steps in your specific workflow tend to loop, so you can put detection where it pays off instead of everywhere. Knowing where an agent is prone to spin, and where it runs clean, is the pattern-level reliability VibeModel builds as the Pattern Intelligence Layer.
Frequently asked questions
Why does my agent repeat the same action even after it fails?
Because nothing tells it the action already failed. Its only memory is the transcript, and a basic reason-act loop has no "already tried this" record, so it treats the step as new. Add external state and loop detection so a repeat is caught and blocked.
Will a bigger model stop the looping?
Not reliably. Looping is a memory and termination gap, not raw capability. A stronger model lowers the rate but still loops without a step cap, a finish tool, and progress tracking. The MAST data shows termination-unawareness concentrated in failed runs regardless of model.
What is the simplest fix that always works?
A hard max-iteration cap. It guarantees the agent stops even when it never recognizes completion, which is why production frameworks build it in by default. Pair it with loop detection so you catch the repeat before the cap.
How much waste does looping actually cause?
A lot. One 8B model spent 26.4 of 40 steps on redundant actions in ALFWorld, about two-thirds of its work. Early-exit methods cut redundant steps 50 to 70% with only minor performance loss.