Short answer. A retry death spiral is when the retries meant to recover from a failure become the main source of load, so a short blip turns into a sustained outage or a runaway bill. A dependency slows, callers retry, the retries add load, the added load makes it slower, which triggers still more retries. For an agent it is worse, because every retried tool call or reasoning step also re-spends tokens. You stop it by making retries polite and bounded: exponential backoff with jitter, a retry budget, and a circuit breaker.

The retries are the load. A slow dependency triggers retries, the retries make it slower, and the loop feeds itself until something breaks it.
Key facts.
- Retries are "selfish": each client improves its own odds at the expense of the shared resource, so uncoordinated retries can keep a dependency down long after the original fault clears (AWS, Timeouts, retries, and backoff with jitter).
- The standard damping is exponential backoff plus jitter, which spreads retries out in time so callers do not synchronize into repeated load spikes (AWS Builders' Library, same source).
- Retry amplification compounds across layers: if three stacked services each retry three times, one user request can become many calls at the bottom, which is how cascading failures form (Google SRE, Addressing Cascading Failures).
- The circuit breaker pattern stops calls to a failing dependency for a cooldown, giving it room to recover instead of being hammered by retries (Nygard, Release It!, 2nd ed.).
Why do retries spiral instead of helping?
Because a retry is just another request, and the thing that is failing is usually failing because of load. When a dependency slows down, every caller hits its timeout at about the same moment and retries. That doubles or triples the traffic hitting an already-struggling service, which pushes its latency up further, which trips even more timeouts, which produces even more retries. The recovery logic has become the load. This is why retries are described as selfish: each client is doing the locally rational thing, improving its own odds, while collectively they keep the dependency pinned down. The original fault might have lasted two seconds, but the retry storm it triggered can last until someone sheds the load by hand.
Why is this worse for an agent?
Because an agent's retry is not a cheap network call, it is another full model invocation. When a tool call returns a rate-limit error or times out, a naive agent loop simply tries again, and each attempt re-sends the growing context and burns more tokens. So an agent retry spiral spends two resources at once: it piles load onto the failing dependency like any client, and it multiplies your token bill on every loop. Worse, agents often retry on things that are not transient at all, like a malformed request the model keeps reproducing, so the loop never naturally ends. The same blip that a well-behaved client would ride out becomes, for an unbounded agent, an open-ended drain on both the dependency and your budget.
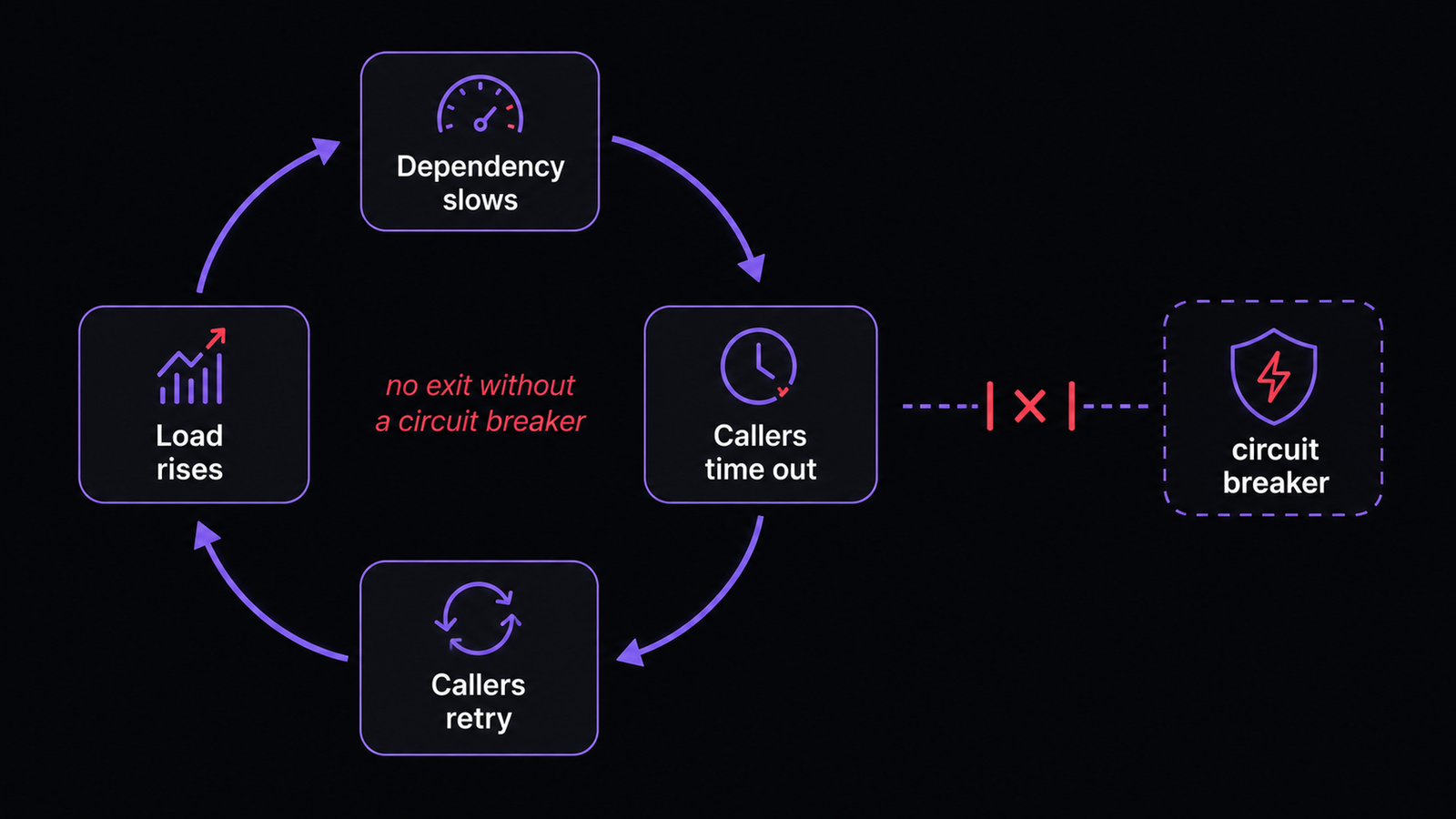
The death spiral as a loop. Each lap adds load, and without a circuit breaker or backoff the loop has no exit.
What turns a small blip into a full outage?
Synchronization and the absence of a limit. If every caller retries on the same fixed schedule, their retries line up into repeated waves that hit the dependency in lockstep, a thundering herd. Add layered retries, where each service in a chain retries the one below it, and the call volume at the bottom multiplies, three retries times three layers is nine, and so on. With no retry budget and no circuit breaker, nothing in the system is allowed to say "stop trying for now." That is the difference between a two-second hiccup and an hour-long incident: not the size of the original fault, but whether the recovery traffic was bounded and spread out, or unbounded and synchronized.
How do you stop the spiral?
| Control | What it does | How |
|---|---|---|
| Backoff with jitter | De-synchronizes retries | Wait exponentially longer each attempt, plus a random offset, so callers do not retry in lockstep |
| Retry budget | Caps total retry load | Allow retries only up to a small fraction of normal traffic; beyond that, fail fast |
| Circuit breaker | Gives the dependency room | After repeated failures, stop calling it for a cooldown, then probe before resuming |
| Cap attempts | Guarantees an exit | A hard max-retry count, then escalate instead of looping |
| Idempotency | Makes retries safe | Keys so a repeated call cannot double-charge or double-write |
The strategic point is that retries are not free safety, they are load you are choosing to add at the worst possible moment, so they have to be governed. Spread them out with jitter, cap them with a budget and a hard limit, and put a circuit breaker in front of anything that can get overwhelmed, so a struggling dependency gets room to recover instead of a beating. For agents, add the token dimension: treat a retry as a spend decision, not a reflex. Knowing which failures in your workflow are genuinely transient and worth one bounded retry, and which are dead ends to escalate immediately, is the pattern-level reliability VibeModel builds as the Pattern Intelligence Layer.
Frequently asked questions
What is a retry death spiral?
It is when retries become the dominant load on a failing dependency, so the recovery traffic keeps it down. A slow service triggers retries, the retries add load, the load slows it further, and the loop feeds itself until something external breaks it.
Aren't retries supposed to improve reliability?
Only when they are bounded and spread out. Uncoordinated retries are "selfish": each helps one caller while collectively overwhelming the shared resource. Backoff with jitter, a retry budget, and a circuit breaker are what make retries safe.
Why is a retry spiral expensive for AI agents specifically?
Because each agent retry is a full model call that re-sends context and spends tokens. So a spiral hits two resources at once: load on the failing tool and a climbing token bill, and unbounded agents often retry non-transient errors that never resolve.
What is the single most important fix?
A circuit breaker plus a hard retry cap. The breaker stops hammering a failing dependency so it can recover, and the cap guarantees the loop exits and escalates instead of running forever. Add backoff with jitter so retries never synchronize.