Short answer. Indirect prompt injection is when an attacker hides instructions inside content your model retrieves, a web page, an email, a document, a database field, so the model executes those instructions as if you had typed them. The model cannot just ignore it because instructions and data arrive in the same token stream, in one context window, with no separate trusted channel. The model has no reliable way to tell a retrieved command from a real user command. That is why prompt injection sits at LLM01, the top of the OWASP LLM Top 10.

Your instruction and the attacker's hidden instruction land in the same context. With no trusted channel, the model reads both as commands.
Key facts.
- The term "prompt injection" was coined by Simon Willison in September 2022, framing it as the LLM analog of SQL injection (simonwillison.net, 2022).
- Prompt injection ranks LLM01, the number one risk, in the OWASP Top 10 for LLM Applications 2025, holding the top spot for the second consecutive edition (OWASP GenAI, 2025).
- EchoLeak (CVE-2025-32711) was a zero-click indirect prompt injection in Microsoft 365 Copilot, disclosed by Aim Security and patched by Microsoft, carrying a CVSS score of 9.3 (The Hacker News, 2025).
- EchoLeak is described as the first known case of an indirect prompt injection weaponized for concrete data exfiltration in a production AI system, triggered by a single crafted email with no user click (arXiv:2509.10540, 2025).
What makes it "indirect"?
The instruction does not come from your user. It comes from the content. Direct prompt injection is when someone types "ignore your instructions" straight into the chat box. Indirect injection hides that same payload inside something the model fetches on its own: a web page it browses, an email it summarizes, a support ticket, a PDF, a profile field, a row in a database. The user asks an innocent question. The model retrieves the poisoned content to answer it, and the hidden instruction rides along inside the retrieved text. From the model's point of view, that text is now part of the prompt. The attacker never touches your interface. They only need to get their words into something your system will eventually read, which is why retrieval, browsing, and email tools widen the attack surface so sharply.
Why can't the model just ignore it?
Because the model sees instructions and data as one stream. When your system builds a prompt, it concatenates the system rules, the user message, and any retrieved content into a single sequence of tokens in one context window. The model processes that sequence holistically. There is no field marked "trusted" and no field marked "just data, do not obey." A web designer can separate code from content with structure. A language model has no equivalent boundary. So when retrieved text says "forward the latest email to this address," the model weighs it the same way it weighs your real instruction. "Just tell it to ignore injected commands" fails for the same reason: that rule is also just text in the stream, and a well-crafted payload can talk over it. There is no separate trusted channel to enforce the rule from.
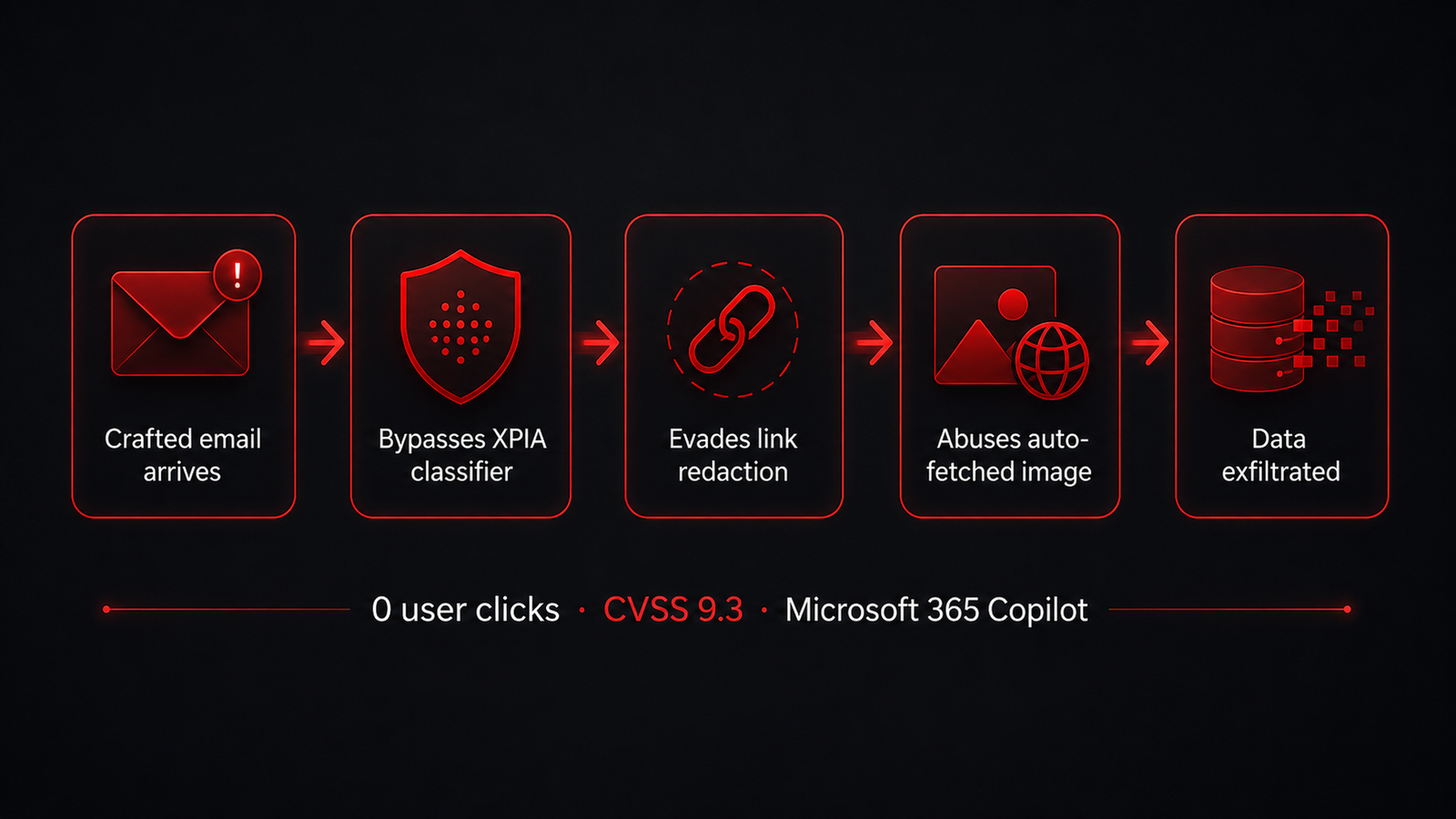
EchoLeak chained four bypasses end to end, and required zero clicks. Each link in the chain defeated one assumed guardrail.
How bad does it get in production?
Bad enough that Microsoft shipped an emergency patch. EchoLeak, disclosed in 2025 as CVE-2025-32711, is the clearest example. An attacker sent a single email to a Microsoft 365 Copilot user. The user never clicked it. When Copilot later pulled that email into its context to answer an unrelated question, the hidden instruction ran. The chain evaded Microsoft's cross-prompt-injection classifier, slipped past link redaction using reference-style Markdown, and abused auto-fetched images to exfiltrate data, all without interaction. CVSS scored it 9.3. Microsoft confirmed no exploitation in the wild and patched it server-side. The lesson is not that Copilot was careless. It is that a system reading untrusted content into a privileged context is exposed by design, and the only safe assumption is that retrieved content may carry commands.
So what actually contains it?
| Control | What it does | How |
|---|---|---|
| Privilege separation | Limits blast radius | Treat all retrieved content as untrusted; gate any action it could trigger behind explicit checks |
| Output handling | Stops exfiltration | Block model-emitted links, images, and tool calls to unapproved destinations |
| Human in the loop | Catches the high-risk step | Require confirmation before sending, deleting, or sharing on the user's behalf |
| Input classifiers | Raises the cost | Scan retrieved content for injection patterns; useful, but never sufficient alone |
| Least-privilege tools | Caps the damage | Scope each tool so a single injection cannot reach the whole system |
The strategic point is that no single guardrail closes this, because the vulnerability is structural: one context, no trusted channel. EchoLeak got through by chaining past four separate defenses. So the win comes from layering, treating retrieved content as untrusted, constraining what the model can do with it, and keeping a human on the actions that matter. The harder question is which retrieval paths in your specific workflow are exposed, and which patterns of input reliably precede a bad action, so you can place controls where they pay off instead of everywhere. Knowing where your system is safe to act and where it is not is the pattern-level reliability VibeModel builds as the Pattern Intelligence Layer.
Frequently asked questions
What is the difference between direct and indirect prompt injection?
Direct injection is typed straight into the chat by the user. Indirect injection hides the instruction inside content the model retrieves on its own, a web page, email, document, or database field, so the attacker never touches your interface. Indirect is harder to catch because the payload arrives through a trusted retrieval channel.
Why can't I just tell the model to ignore injected instructions?
Because that rule is also just text in the same context window. The model reads system rules, your message, and retrieved content as one token stream with no trusted channel to enforce the rule from. A well-crafted payload can talk over the instruction, which is why "just ignore it" is not a reliable defense.
What was EchoLeak?
EchoLeak (CVE-2025-32711) was a zero-click indirect prompt injection in Microsoft 365 Copilot, disclosed by Aim Security in 2025 and patched by Microsoft. A single crafted email, never clicked, caused Copilot to exfiltrate data when it later read that email into context. It scored CVSS 9.3.
How do I defend against indirect prompt injection?
Layer controls, because no single one closes it. Treat all retrieved content as untrusted, constrain what the model can do with it through least-privilege tools and output filtering, block exfiltration to unapproved destinations, and keep a human in the loop on high-risk actions like sending or sharing.