
Short answer. Your agent hallucinates the value not because the data is missing from your database, but because the retrieval layer never delivered it to the model intact, ranked high enough, and placed where the model would actually use it. The data exists. The pipeline leaked before the model started writing.
The record is right there in your database. The agent still invents a value. The instinct is to blame the model, reach for a bigger one, or rewrite the prompt. Almost always, the model understood the request fine. The grounding system that was supposed to feed your data to the model is what leaked, and the leak is invisible because the answer still reads fluent and confident.
What is actually happening when the data exists but the answer is wrong?
Retrieval-augmented generation does not remove hallucination; it moves it upstream, from the model's memory to the retrieval and assembly step (Barnett et al., Seven Failure Points of RAG). If the correct chunk is not fetched, not ranked high enough, or not positioned where the model attends, the model does what models do under pressure to answer: it produces a plausible value from its training instead of refusing. The database was never the problem. The pipeline that was supposed to ground the model on it was.
Why does retrieval miss a fact that is sitting right there?
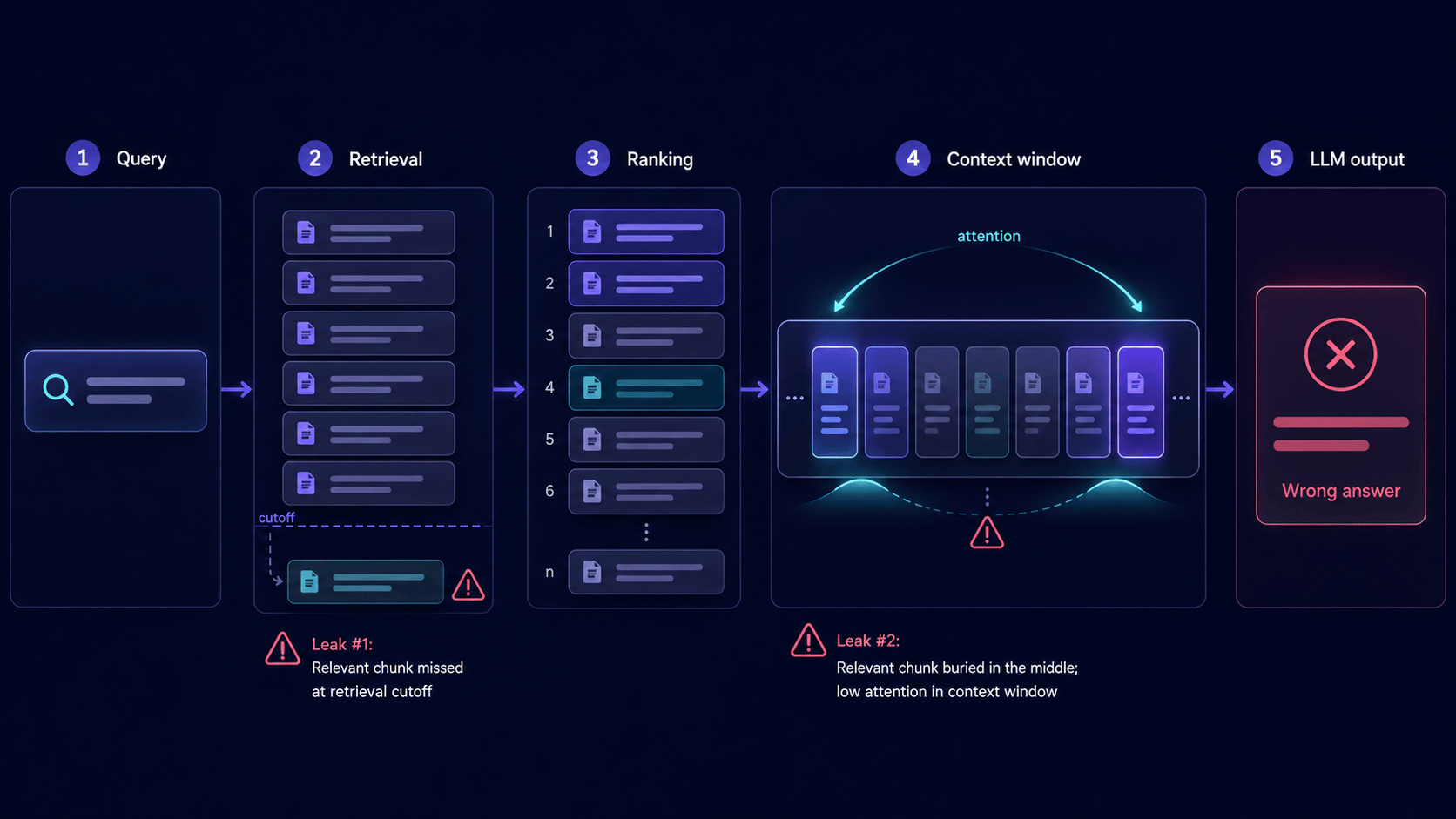
Three named mechanisms. Retrieval miss: the relevant chunk is indexed, but embedding similarity scores it below the top-k cutoff, so it is never pulled, common with ambiguous queries or exact identifiers like codes and case numbers. Embedding mismatch: a general-purpose embedding model maps the query and the truly relevant chunk to distant vectors, so cosine similarity favors a thematically similar but factually wrong chunk. Ranking failure: superficially similar chunks outrank the precise one, which sits just below the cutoff or gets dropped at the token limit. In all three the right data exists in the index and is simply never shown to the model. This is why a bigger model does not fix it: the bottleneck is what reaches the context, not how well the model reasons over it.
Why does chunking make the agent invent a value?
Fixed-size chunking splits documents at arbitrary token boundaries, which severs a fact from the context that makes it usable. A rule and its exception, a table row and its header, a record and one of its fields end up in different chunks. Retrieval then returns a partial piece, and the model gap-fills the missing field with an invented but plausible value rather than reporting that it could not find it. The fact was in your source system; chunking cut it in half before the model ever saw it. Semantic or structure-aware chunking, which splits at natural topic and section boundaries and respects tables, keeps facts intact and is one of the highest-leverage fixes.
Why does the agent ignore a fact it did retrieve?
Even when the right chunk reaches the context window, the model can under-weight it. Liu et al. documented the lost-in-the-middle effect: accuracy is highest when key information sits at the very start or end of the context and drops sharply when it sits in the middle, a U-shaped curve that holds even for long-context models. So with a large top-k and verbose chunks, the correct evidence is present but buried, and the model falls back to parametric guessing. Retrieval succeeded and the answer is still wrong, which is exactly why teams who only measure whether a document was retrieved miss the failure.
A real case: the data existed and the agent still got it wrong
In 2024 an Air Canada customer asked the airline's chatbot about bereavement fares. The bot confidently described a policy allowing a retroactive discount claim. The correct policy existed on Air Canada's own site and did not work that way. The customer relied on the wrong answer, was denied, and took it to the British Columbia Civil Resolution Tribunal, which ruled against Air Canada and awarded damages, rejecting the argument that the chatbot was a separate entity responsible for itself. The ground truth was in the source system. The agent synthesized a confident, wrong version anyway. That is this failure mode in public, with a legal ruling attached.
How do you stop it?
The unifying fix is to stop treating retrieval as fire-and-forget. Hybrid search (sparse BM25 plus dense vectors) and a reranker get the right chunk in front of the model. Semantic chunking keeps facts whole. Metadata filtering removes stale and contradictory versions. Corrective or agentic RAG lets the agent check whether its answer is actually supported and re-retrieve or escalate if not. And a grounding check that permits an honest "I could not find this" stops the silent gap-fill. None of these is a bigger model. Every one of them is an engineering layer above the model. That layer, knowing where your retrieval is trustworthy and where it is guessing, is what VibeModel builds as the Pattern Intelligence Layer.
Frequently asked questions
Is a bigger or smarter model the fix for this?
No. The failure is in the grounding layer: what gets retrieved, ranked, and positioned before the model writes. A stronger model reasons better over its context, but if the right fact never reached that context, or was buried in the middle of it, the answer is still wrong, just more fluently.
How do I tell a retrieval failure from a model failure?
Trace whether the correct chunk was retrieved and where it sat in the context. If it was never retrieved, that is a retrieval or ranking problem. If it was retrieved but ignored, that is lost-in-the-middle or a weak grounding check. Measuring only the final answer hides which one it is.
Does RAG eliminate hallucination?
No. RAG moves the hallucination surface from the model's memory to the retrieval and assembly stage. Done well it sharply reduces hallucination; done with fixed chunking, weak ranking, and no grounding check, it produces confident wrong answers over data that exists.
What is the single highest-leverage fix?
Add a reranker and a grounding check. Reranking gets the right chunk to the top of the context; the grounding check verifies every claim is supported by a retrieved source and lets the agent say "not found" instead of inventing a value.