Two conversations this month, from two very different companies, kept landing on the same point.
The first was a Head of Product at a Series C company. Sixty minutes into the call, after she had walked me through the team's roadmap, the OKRs, the model registry, the eval pipeline, she said: "We build 3 models a year. None of them make it to production."
She had eight data scientists. Two PhDs. The talent was real. The compute was fine. The data was honest. I asked her what was blocking the deploy. Her answer was four words. "We don't trust them enough."
The second conversation was a few weeks earlier, with a Wharton professor's column rather than the person himself. The framing was that foundation models can't act as their own deployment consultants. They can't map a process. They can't run change management. So enterprises hire humans to do all of that around the model. I read it twice. Then I disagreed with him in the comments.
Both conversations were about the same gap. Different vocabulary.
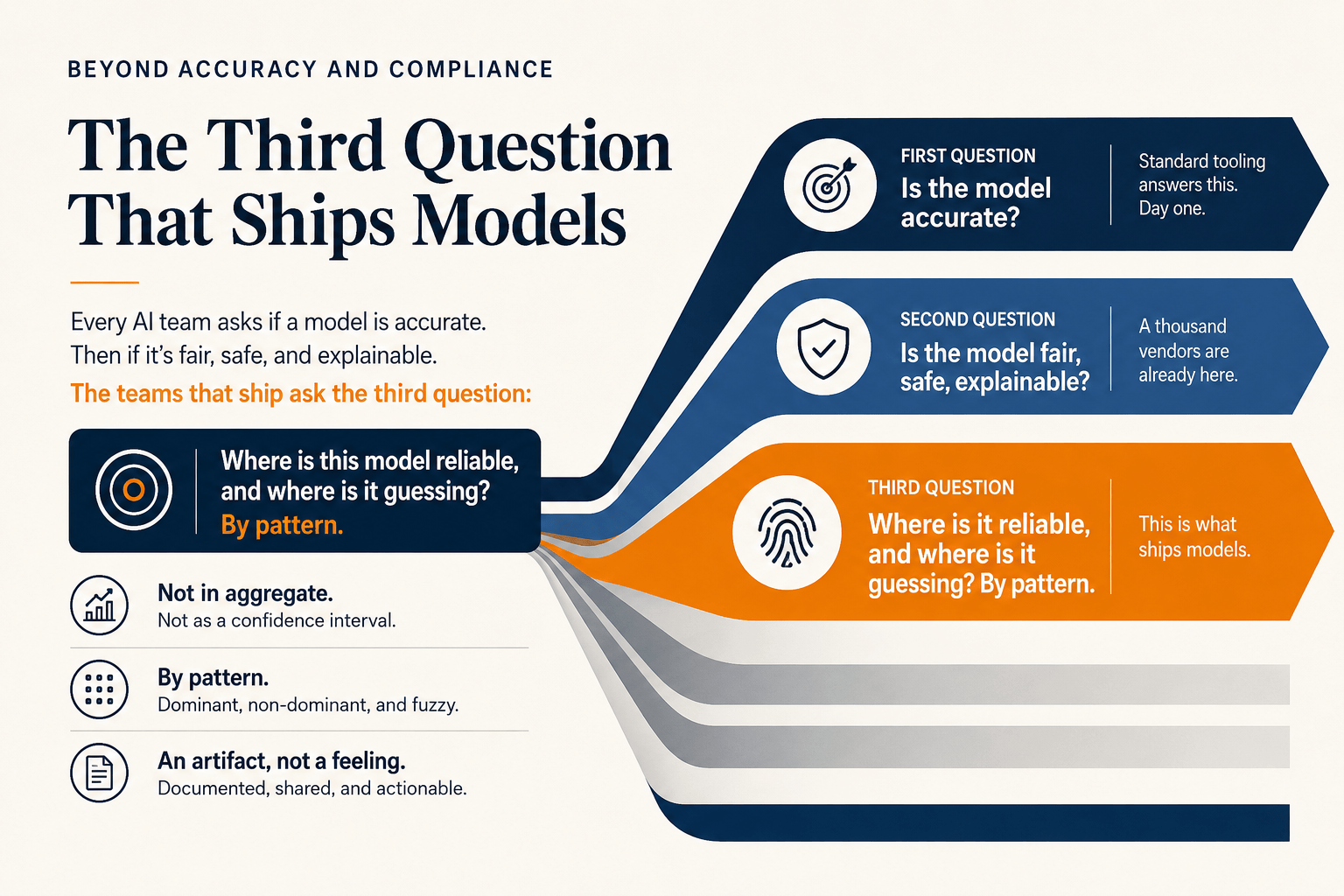
The two questions every AI team already asks
Most teams I've talked to (150-something CXO interviews and counting) ask two questions about their AI work, in order.
The first question is "is the model accurate?" Standard tooling answers this. Accuracy scores, confusion matrices, eval suites, leaderboards. The team can answer it on day one with a benchmark and a deploy script.
The second question is "is the model fair, safe, explainable?" This one is harder, but a thousand vendors are already racing to sell answers. Audit trails. Bias detection. SHAP plots. Compliance dashboards.
Both questions are real. Both are necessary. Neither is the question that's actually blocking deployment in the conversations I keep having.
The third question
The third question is the one most teams haven't named yet, even though every senior data scientist in their building is silently answering it every week. It's this: where is this model reliable, and where is it guessing?
Not in aggregate. Not as a confidence interval. By pattern.
The 95%-accurate payment-prediction model that's 100% on people who already pay and useless on the 5% who don't isn't an accuracy problem. It's a third-question problem. The model is reliable on the dominant pattern, people who pay on time, and blind on the minority pattern, people who don't, that is the entire reason the model exists.
The 8-data-scientist team on V8 of the same churn model isn't a methodology problem in the abstract. It's a third-question problem. Every iteration of V1 through V8 was a different attempt to push aggregate accuracy on a different slice of the data. Nobody was answering which patterns the model is reliable on and which it never saw enough times to learn. Without that answer, V9 is going to be the same shape as V8.
The credit-risk model sitting in a folder on a shared drive at the bank isn't a compliance problem. It's a third-question problem in disguise. Compliance doesn't want explainability in the abstract. They want a document that says: this model is reliable on these patterns and should be allowed to make these decisions, and on those patterns it isn't, so a human should be in the loop. That document is the third-question answer in audit-pack form.
Why the third question is invisible
Two reasons. One: the language is missing. Most teams don't have separate names for dominant patterns, non-dominant patterns, and fuzzy patterns. They have one word: accuracy. Without the language, the conversation collapses into the first question, which has tooling, and the second question, which has a market.
Two: the artifact is missing. Even the teams who feel the third question don't have a place to write the answer down. There's no slot in the eval pipeline for "the model is reliable on these six pattern clusters, blind on these two, and probably overfit on this third." The dashboards don't have that row. The reports don't have that column. So the answer lives in the head of the most senior data scientist, who burns out in eighteen months and takes the answer with them.
What this means for the next 90 days of your AI roadmap
If your team is on V5+ of the same model and is still framing the problem as a tuning issue, the answer probably isn't more iterations. It's the third question. Map the patterns the model is reliable on, the ones it isn't, and the ones it never saw. Ship the V5 you've got, scoped to the patterns it actually handles. Plan V6 around closing one specific blind spot.
If your team has a working model that compliance won't sign off on, the answer isn't a SHAP plot. It's the third question, rewritten as an audit artifact. Tell the regulator which patterns the model is allowed to act on, which patterns route to a human, and how the line is monitored.
If your team is hitting a 90-something-percent accuracy plateau on a customer-facing prediction, the answer probably isn't a bigger model. It's the third question, applied to the minority class. The 5% is where the value is. Pick the model that handles the 5% best, accept that aggregate accuracy will look lower on paper, and ship the version that's actually useful.
This is the layer we're building. We call it the Pattern Intelligence Layer. It sits between the model and the deployment decision and answers the third question explicitly, with named patterns, confidence reads, and an artifact that compliance, product, and engineering can all read.
So here's the question worth sitting with: what's the third question your team is silently answering this quarter, and where would it live if you wrote it down?