I spent the last nine months in 150+ conversations with CXOs about why AI breaks in production. Different industries, different stacks, different budgets. The conversations should have been all over the map. They weren't.
Three patterns kept surfacing, and the more I heard them, the more I realized those weren't isolated observations. They were symptoms of a single problem I hadn't named yet. This is the consolidation: three CXO voices in their own words, the underlying pattern beneath them, and one quick test you can run on your own stack this week.
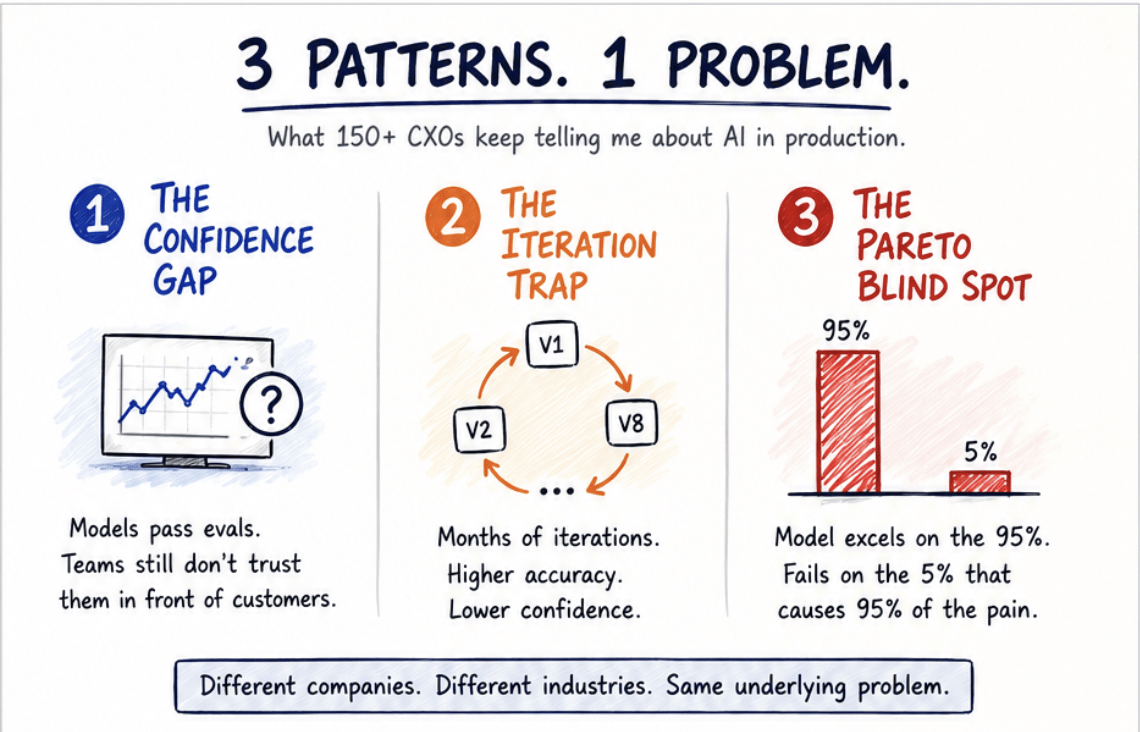
1. The Confidence Gap
A Head of AI at a $500M company sat down across from me last quarter. She had 8 data scientists. Two PhDs. She named four projects they'd shipped that quarter. Then she said the line that stayed with me:
"We have the talent. I'm not confident enough to put their models in front of customers."
She wasn't talking about model accuracy. She was talking about something her dashboards weren't measuring. The Confidence Gap is the distance between "the model passed evaluation" and "I trust this in front of a paying customer." Most teams treat that distance as a soft-skill problem, a culture problem, a data quality problem. It isn't. It's a measurement problem.
Nothing in the standard MLOps stack tells the Head of AI where the model is reliable, where it's brittle, where it's guessing, and where confidence silently collapses under edge conditions. Until that's instrumented, every production deployment carries the same hidden risk. And the people closest to the model know it. So they hesitate.
2. The Iteration Trap
The second voice was a Head of Product at a Series C company. At the end of a 60-minute call, she told me: "We build 3 models a year. None make it to production." I asked why. She paused and said: "We don't trust them enough." Same sentence. Different company. Different stack.
Here's what the Iteration Trap actually looks like inside the team. Model V1 hits 87% accuracy in development. Looks promising. Push to staging. Real edge cases appear. Accuracy drops to 76%. Team rebuilds. V2 hits 89% on staged data. Edge cases shift again. More retraining, more tuning, more dashboards. Eight months later the team is on V8, nobody knows which version is actually closest to production-ready, and nobody trusts the one that scored highest yesterday.
The standard tooling handles the easy 30%: pick a model, tune hyperparameters, track experiments, optimize benchmarks. What it doesn't do is surface non-dominant patterns, identify staging behaviors likely to fail in production, map fuzzy edge-case regions, expose where training coverage exists but confidence does not, or detect drift before reliability collapses. That's the hard 70%. And until that layer exists, iteration doesn't compound confidence. It compounds uncertainty.
3. The Pareto Blind Spot
The third voice was the founder of a B2B payments analytics platform. He showed me a model his team was proud of: "95% accuracy on payment delay prediction." Then he explained what was actually happening. The model was nearly perfect on customers who always paid on time, and almost useless on the 5% who paid late.
That 5% had inconsistent behavior, sparse signals, minority patterns, rare-but-important failure cases. Meanwhile 90% of revenue came from four or five enterprise accounts, and the other 10% came from 150 smaller ones. Classic Pareto distribution. The model got world-class at the majority case and silently failed on the edge cases that mattered most.
This is where teams confuse rarity with irrelevance. The 5% that creates 95% of operational pain is not noise. It has structure. But that structure is buried under 19x more data pointing the other direction. Standard models don't naturally discover minority patterns. They average them away.
The pattern under the patterns
Three companies. Three CXOs. Three completely different surface-level problems. But underneath them was the same issue: every team is solving the easy 30% with off-the-shelf tooling and doing the hard 70% manually.
That hard 70% includes pattern discovery, drift detection, minority-pattern mapping, edge-case classification, confidence calibration, reliability estimation, and workflow-aware monitoring. These are not missing features in your MLOps stack. They are an entirely different layer.
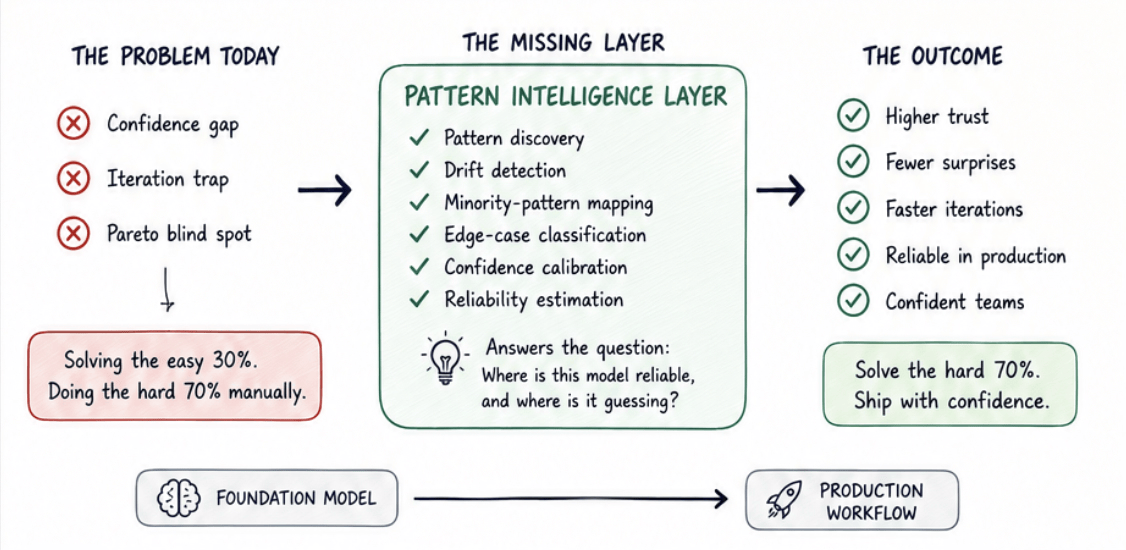
The Pattern Intelligence Layer
We've started calling it the Pattern Intelligence Layer. The layer that sits between the foundation model and the production workflow, and answers the question: where is this model reliable, and where is it guessing? Without that layer, every team I talk to is doing the same manual work privately while pretending the dashboard number means more than it actually does.
One thing to do this week
If you run any model in production, spend 30 minutes answering these three questions in writing.
1. Where does the model do well? Not "production traffic." Be specific: dataset slices, customer cohorts, input distributions, workflow conditions. Slice it precisely.
2. Where does the model break? Identify the 5% causing operational pain, the edge cases, the minority behaviors, the situations where trust collapses. Name the pattern.
3. What signal would tell you the answer has changed? Not just aggregate accuracy. Think distribution shifts, edge-case surface area, class imbalance movement, confidence drift, minority-class degradation.
If your team can't answer those three questions clearly, you're carrying the same hidden risk every CXO above described. The fix is not necessarily a better model. The fix is a documented map of where the model is reliable, where it is uncertain, and where it silently fails. That document is the beginning of the pattern intelligence layer for your team.